

Ruben Arslan @rubenarslan@schelling.pt
- Website
- https://rubenarslan.github.io
- The 100% CI
- http://the100.ci
- Formr.org
- https://formr.org
- https://twitter.com/rubenarslan
Bayescurious evidence enthusiast http://the100.ci
Topics: evolution, ovulation, mutation, intelligence, personality, sexuality, R, open science & source tools.
Joined Feb 2023
RT @alexeyguzey
@leopoldasch exactly like humans




RT @emollick Well this is something else.
Well this is something else.
GPT-4 passes basically every exam. And doesn't just pass...
The Bar Exam: 90%
LSAT: 88%
GRE Quantitative: 80%, Verbal: 99%
Every AP, the SAT...

RT @ianhussey
Please note that you cannot infer that this subtweet is about you because that would be conditioning on the subtweet, which is inferentially problematic.
RT @StuartJRitchie
Pretty much *the No.1* thing you learn NOT to do in science/statistics is to look at graphs that have similar lines and then imply that one thing must be causing the other.
But now loads of very smart people are doing just this, and everyone is nodding along! What's going on!?

I would be interested to hear what someone who knows more about quantile regression thinks about this @alexpghayes @PHuenermund
thanks to @smartin2018, whose LMMSELM package gets an honorary mention, for comments
https://github.com/stephenSRMMartin/LMMELSM
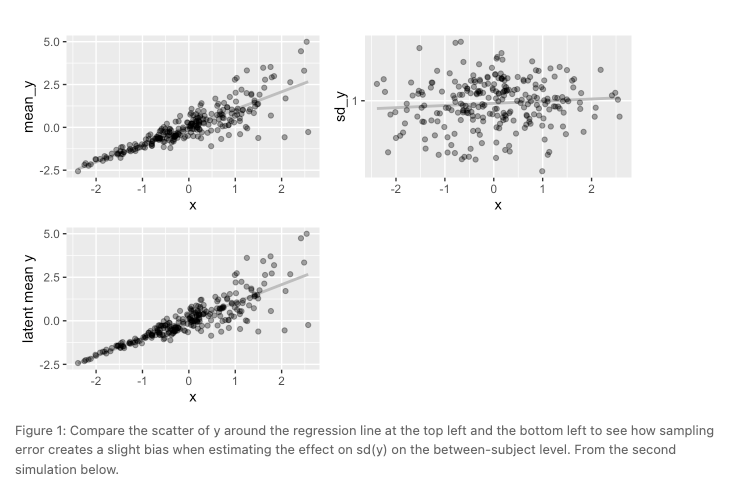
New blog post on the Killingsworth, Kahneman, Mellers paper and censored mixed effects location-scale models.
TLDR: sampling error, censoring, and heterogeneous within-subject variance could all bias the KKM estimates. Better models exist (with brms)
https://rubenarslan.github.io/posts/2023-03-05-multilevel-censored-location-scale-models



RT @maltoesermalte
Thinking deeply is an irregular verb:
I think deeply
You nitpick
He/she [depends on if I like them]
We think deeply
You all are bullies
They [depends] https://twitter.com/ianhussey/status/1042025024402665472
RT @maltoesermalte
Mhmm gotta love the sound of theory building https://twitter.com/rubenarslan/status/1634439044020031490
I don't think there's nothing substantive to these trends, but, man, I don't trust that gang with their thirst for monocausal explanations to get to the bottom of this or anything else really.
Ah yes, the good old "we tried chopping up the data many ways to find a specific three-way-interaction we had in mind". You love to see it in 2023.

Working with Malte is wonderful! If this project interests you, apply, if it doesn't consider developing an interest so you can apply.
---
RT @maltoesermalte
Job opportunity at my lab in a project on privacy in mental health apps, done in collaboration with the Clinical Psych and Psychotherapy division (Thomas Berger). Starts in July, funding for 4 years. If you like open science and research methods, please apply until March 31. ht…
https://twitter.com/maltoesermalte/status/1633425351903772672
RT @ehudkar
@dingding_peng This is cursed.
so I redid the facet titles

in which @Aella_Girl is an exemplary collider, which, all things considered, probably is something she aspires to
---
RT @the100ci
New post! Are representative samples redundant at best? @dingding_peng investigates 3 scenarios: estimating a prevalence, estimating a causal effect in an experiment, and estimating a causal effect (or a correlation!) in an observational study. https://www.the100.ci/2023/03/07/non-representative-samples-what-c…
https://twitter.com/the100ci/status/1633114722680569857
RT @annemscheel
Helpful quality content from @dingding_peng as usual, featuring The Law of @lakens' Guidelines (footnote 13) https://twitter.com/the100ci/status/1633114722680569857



RT @the100ci
New post! Are representative samples redundant at best? @dingding_peng investigates 3 scenarios: estimating a prevalence, estimating a causal effect in an experiment, and estimating a causal effect (or a correlation!) in an observational study. https://www.the100.ci/2023/03/07/non-representative-samples-what-could-possibly-go-wrong/
OK, time to spill it: When you prompt ChatGPT with a Stackoverflow question template to get help with R programming, whose name do you put in as the person answering?
RT @dingding_peng
@rlmcelreath I'm terribly sorry Richard but I saw two of your tweets in close succession and then this just sort of happened.

- Website
- https://rubenarslan.github.io
- The 100% CI
- http://the100.ci
- Formr.org
- https://formr.org
- https://twitter.com/rubenarslan
Bayescurious evidence enthusiast http://the100.ci
Topics: evolution, ovulation, mutation, intelligence, personality, sexuality, R, open science & source tools.
Joined Feb 2023
